

目录
快速导航-

卷首语 | DeepSeek是中国的“斯普尼克时刻”吗?
卷首语 | DeepSeek是中国的“斯普尼克时刻”吗?
-
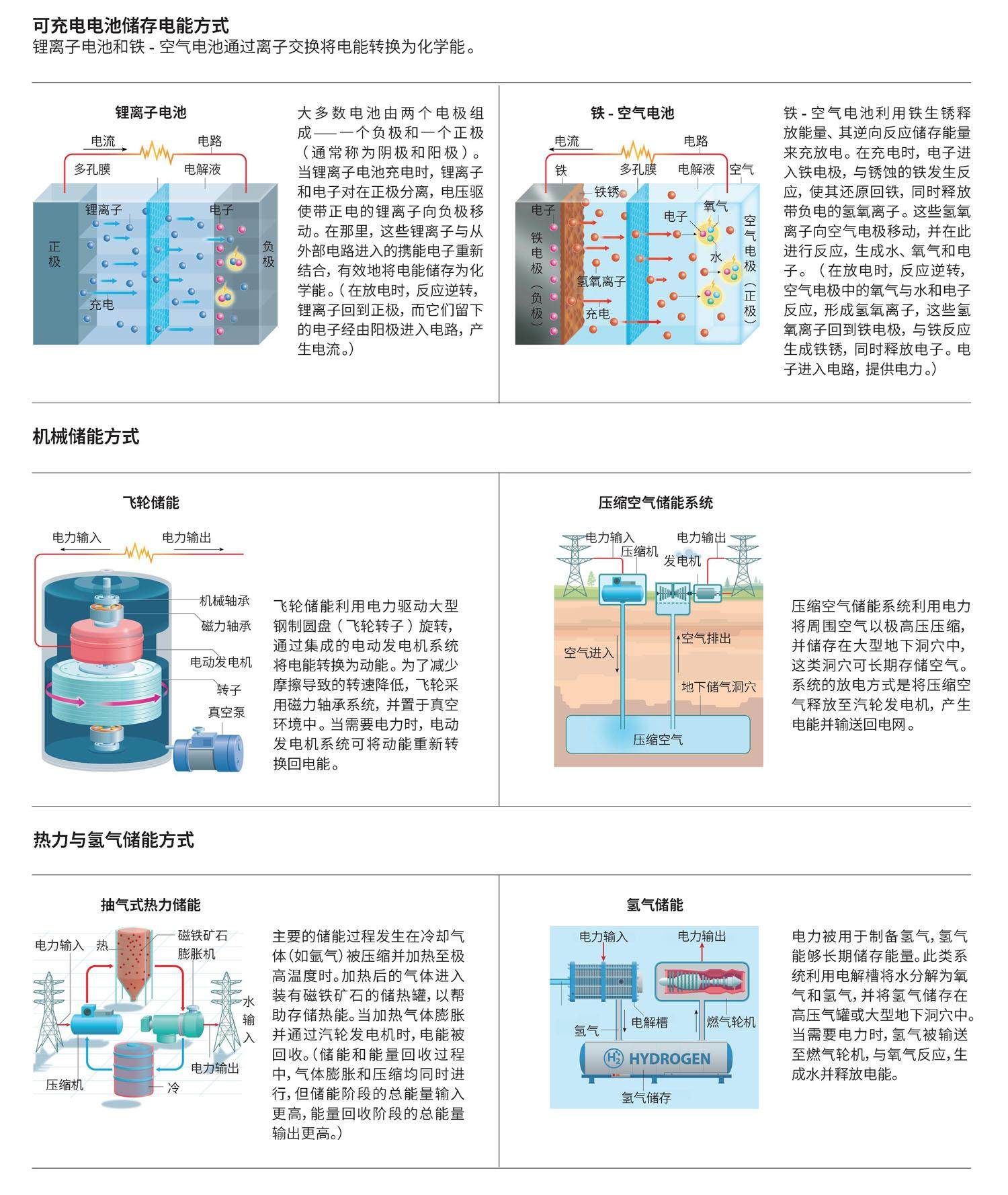
专稿 | 平价开源DeepSeek惊艳全球
专稿 | 平价开源DeepSeek惊艳全球
DeepSeek-R1在推理任务中的表现媲美OpenAI的o1,并向研究人员开放审查。 中国开发的名为DeepSeek-R1的大语言模型作为一种平价开源模型,成了OpenAI的o1这类“推理”模型的竞争对手,令整个科学圈兴奋不已。 这类模型通过逐步生成响应的方式运作,类似于人类的推理过程。这使得它们比之前的语言模型更擅长解决科学问题,并有望在科研中发挥作用。2025年1月20日发布的对R1的初
-
专稿 | DeepSeek竞出的背后
专稿 | DeepSeek竞出的背后
当做量化对冲基金出身的梁文锋进入人工智能研究领域时,他手里囤了上万枚英伟达芯片,组建了一支雄心勃勃的青年才俊队伍。两年后,DeepSeek异军突起。 2025年1月20日,中国一所不知名的科技初创公司DeepSeek发布了他们的最新开源模型DeepSeek-R1,并迅速成为硅谷热议话题。根据该公司撰写的一篇论文,DeepSeek-R1在多个数学和推理基准测试中击败OpenAI o1等业界领先模型
-

科技政策 | 特朗普的“政府效率部”将如何提高效率?
科技政策 | 特朗普的“政府效率部”将如何提高效率?
-

科技政策 | NIH间接成本率政策改革究竟改了什么?
科技政策 | NIH间接成本率政策改革究竟改了什么?
-
智库观察 | 完善语料数据生态,赋能大模型产业发展
智库观察 | 完善语料数据生态,赋能大模型产业发展
人工智能(AI)是新质生产力的典型代表,大模型是全球科技竞争的核心领域,也是引领新一轮产业革命的重要推动力。当前,国内大模型公开语料数据资源匮乏,高质量私域语料数据供给不畅,未形成大模型语料数据优质生态。针对这类问题,我国应率先完善语料数据生态,抢先研发下一代基础大模型,促进人工智能与经济社会发展的深度融合,引领和推动我国新一代人工智能的健康发展。 国内大模型语料数据供给面临三大困境 根据中国
-
科技评论 | AI4S:技术突破、商业落地的机遇与挑战
科技评论 | AI4S:技术突破、商业落地的机遇与挑战
人工智能赋能科研(AI for Science, AI4S)是当前人工智能发展新前沿,也是促进科技变革的关键部分。关于AI4S的发展机遇与挑战,上海市科学学研究所邀请国内高校院所及企业的多位一线青年专家进行了座谈,并梳理了各位专家的主要观点,以飨读者。 对AI4S的政策支持应从AI重构科学研究的实践本质出发 封凯栋 北京大学政府管理学院公共政策系主任 在科技政策研究领域,学者对人工智能普遍
-

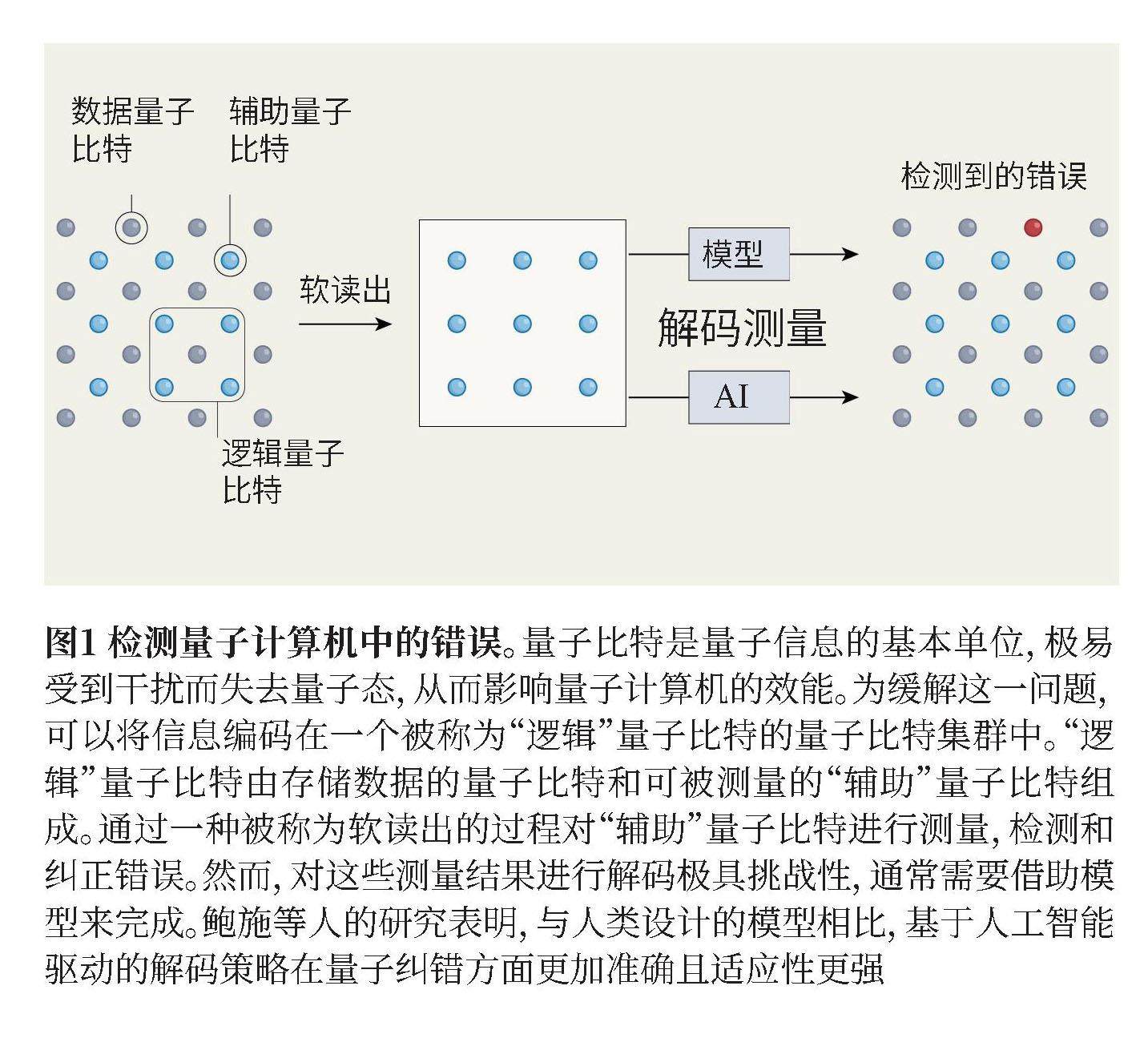
科技传播智见 | 科学素养问题的探讨
科技传播智见 | 科学素养问题的探讨




















 登录
登录