

目录
快速导航-

特约稿件 | 社交媒体网络辟谣回音室效应分析模型及实验研究
特约稿件 | 社交媒体网络辟谣回音室效应分析模型及实验研究
-
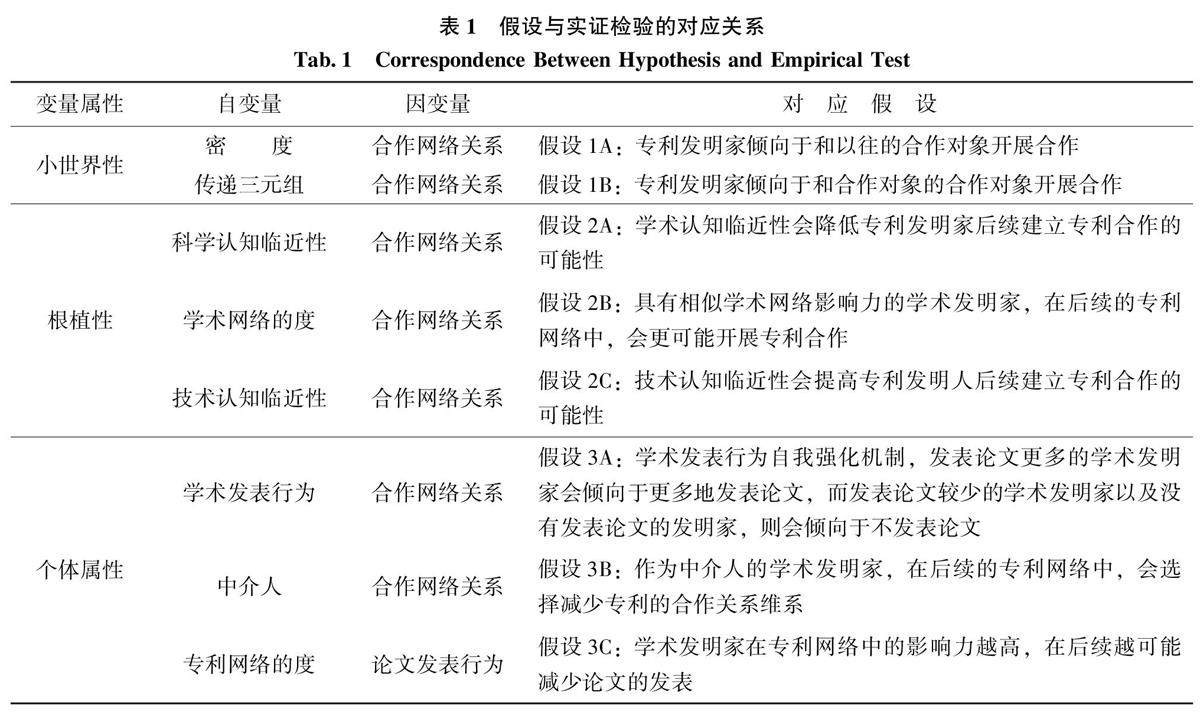
特约稿件 | “跨界发表”:学术发明家的学术发表对其专利网络的动态演化影响
特约稿件 | “跨界发表”:学术发明家的学术发表对其专利网络的动态演化影响
-
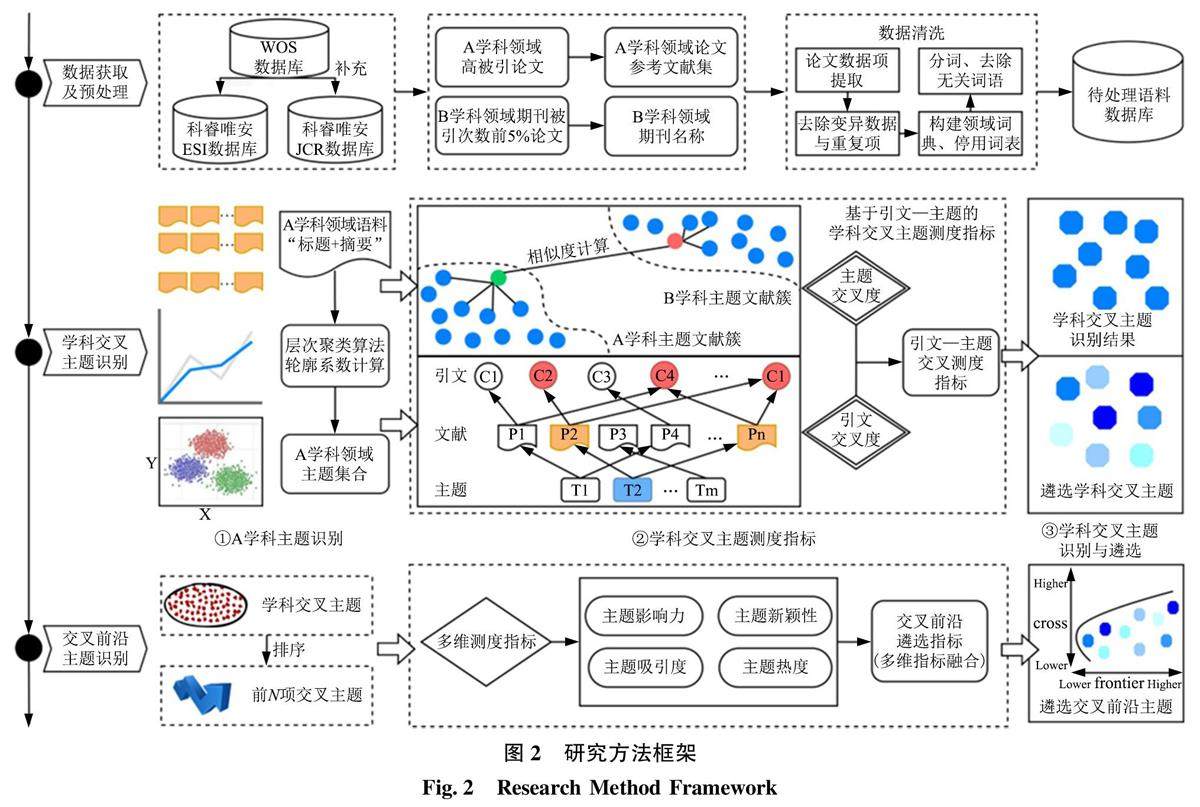
情报理论与前瞻观点 | 基于引文—主题双重测度的交叉前沿识别研究
情报理论与前瞻观点 | 基于引文—主题双重测度的交叉前沿识别研究
-
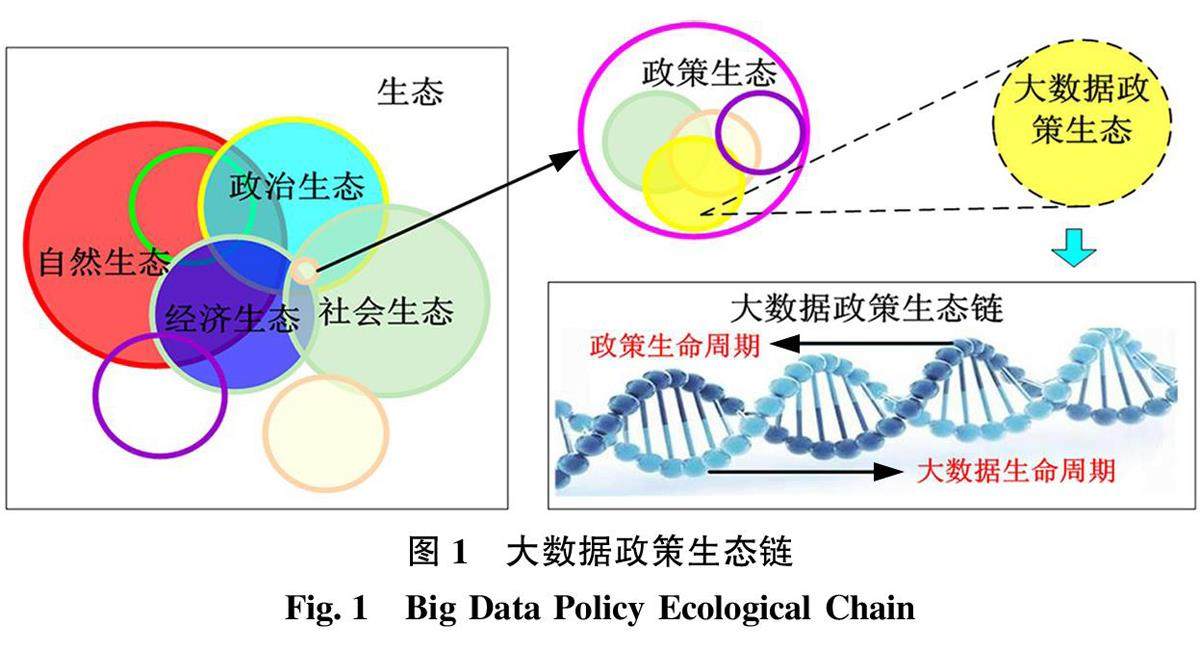
情报理论与前瞻观点 | 大模型视域下大数据政策生态链研究
情报理论与前瞻观点 | 大模型视域下大数据政策生态链研究
-
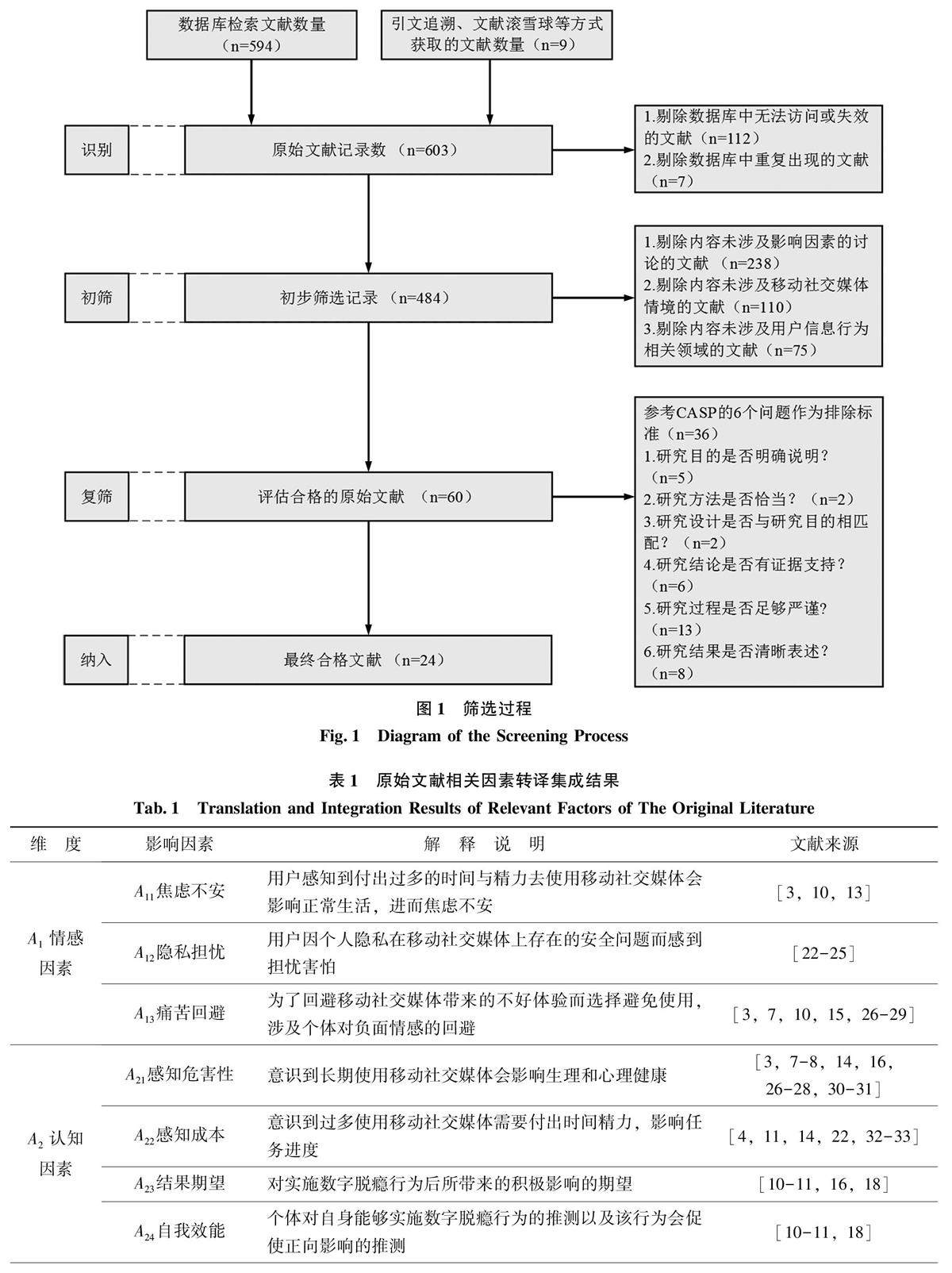
信息行为与用户研究 | 移动社交媒体用户数字脱瘾行为影响因素识别及引导策略研究
信息行为与用户研究 | 移动社交媒体用户数字脱瘾行为影响因素识别及引导策略研究
-
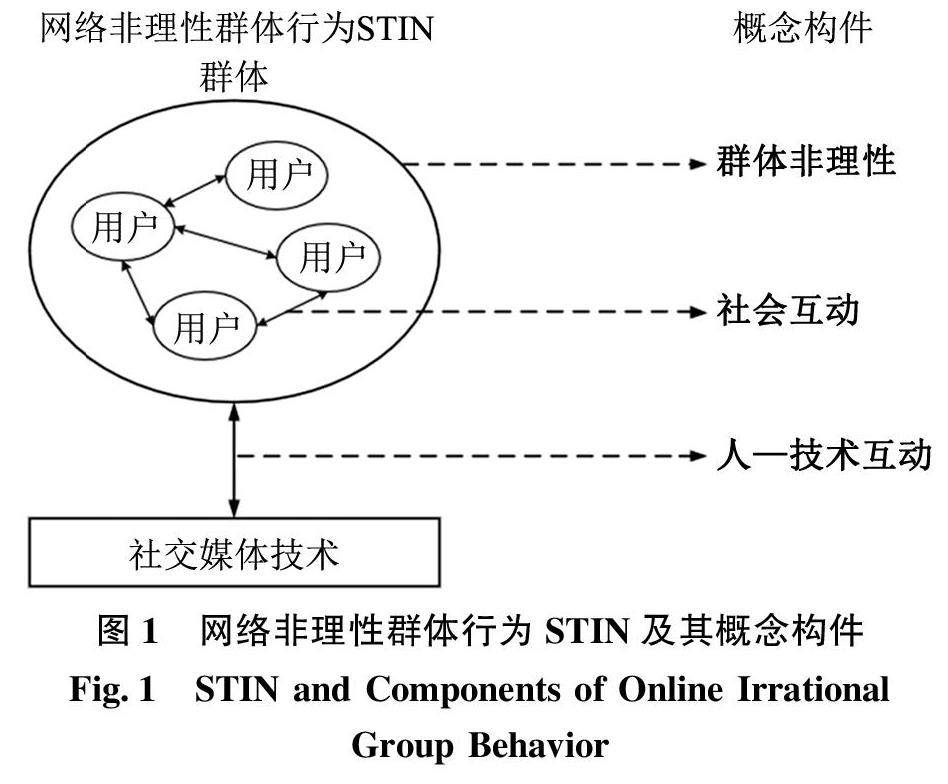
信息行为与用户研究 | 网络非理性群体行为概念解析与理论框架构建
信息行为与用户研究 | 网络非理性群体行为概念解析与理论框架构建
-
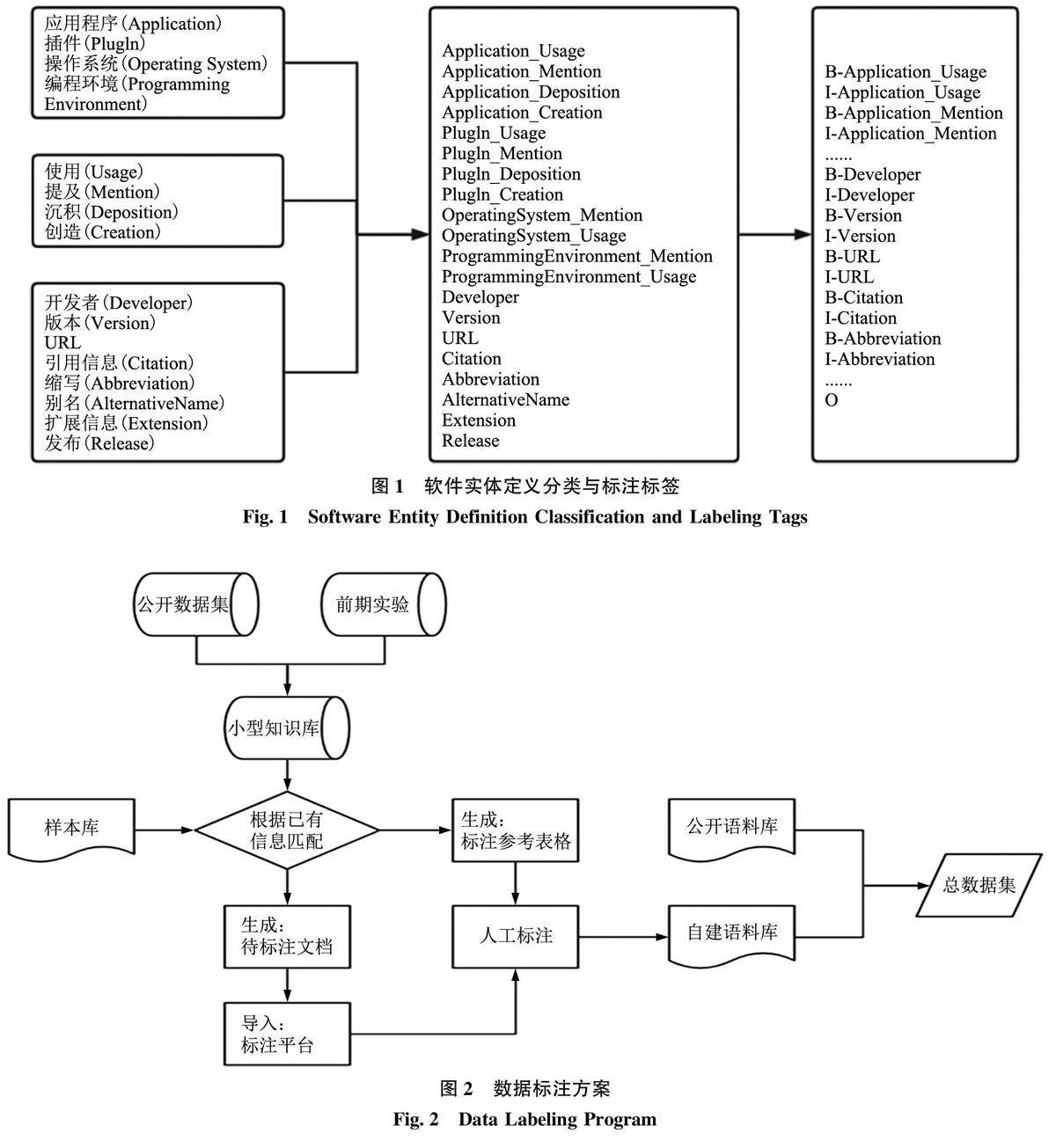
信息行为与用户研究 | 基于SciBERT-BiLSTM-CRF-wordMixup的软件实体识别研究
信息行为与用户研究 | 基于SciBERT-BiLSTM-CRF-wordMixup的软件实体识别研究
-

信息行为与用户研究 | 可拓理论在技术演化与预测中的应用潜力
信息行为与用户研究 | 可拓理论在技术演化与预测中的应用潜力
-
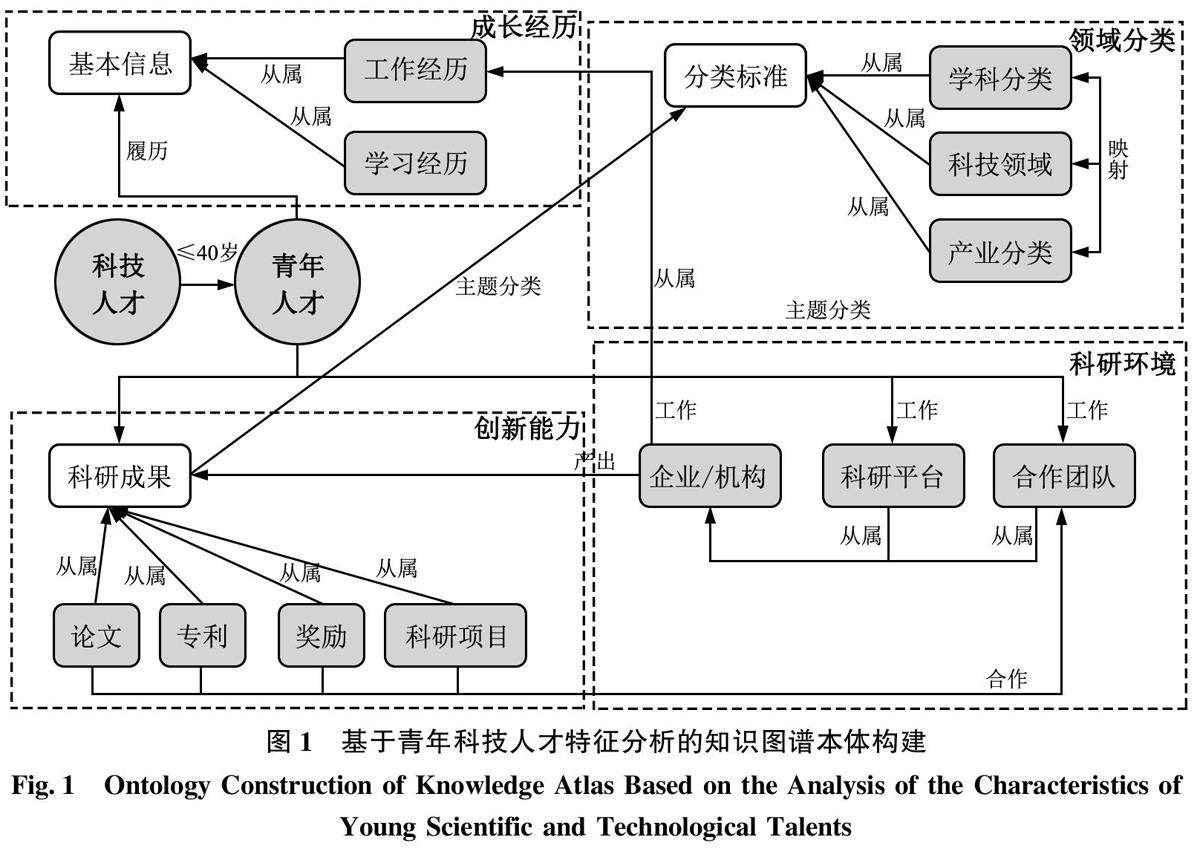
信息行为与用户研究 | 基于三层数据治理的青年科技人才知识图谱构建与应用实践
信息行为与用户研究 | 基于三层数据治理的青年科技人才知识图谱构建与应用实践
-
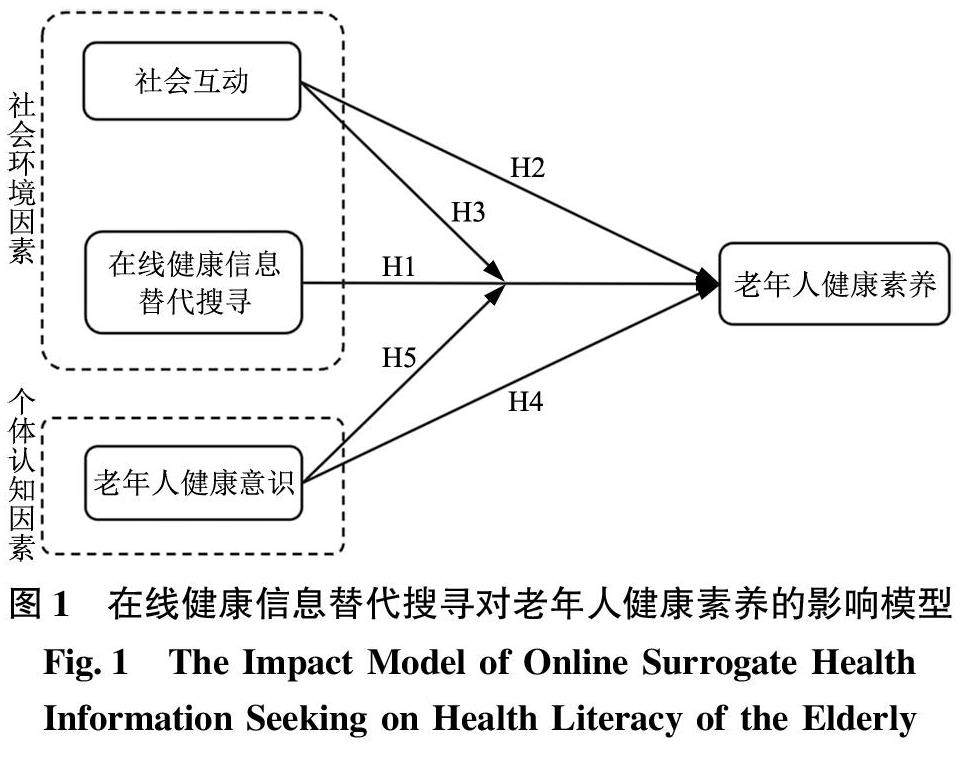
数智健康与智慧医养 | 在线健康信息替代搜寻对老年人健康素养的影响研究
数智健康与智慧医养 | 在线健康信息替代搜寻对老年人健康素养的影响研究
-
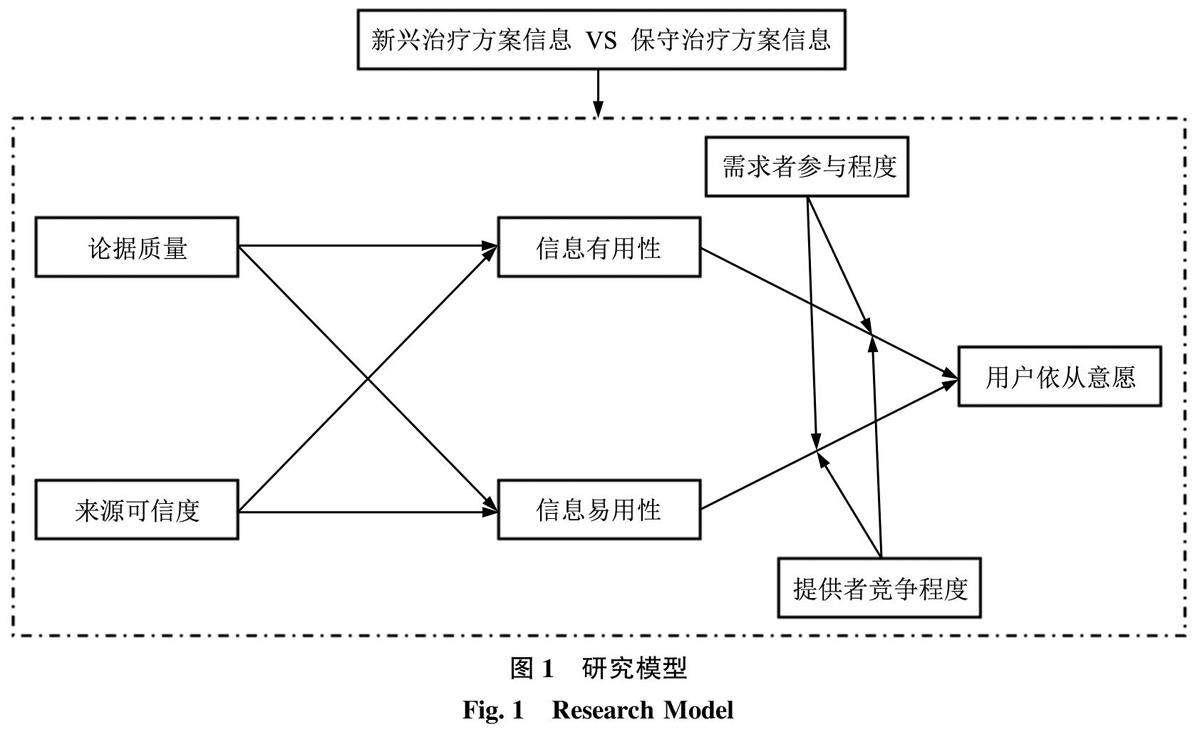
数智健康与智慧医养 | 在线健康信息用户依从意愿的关键因素与组态路径
数智健康与智慧医养 | 在线健康信息用户依从意愿的关键因素与组态路径
-
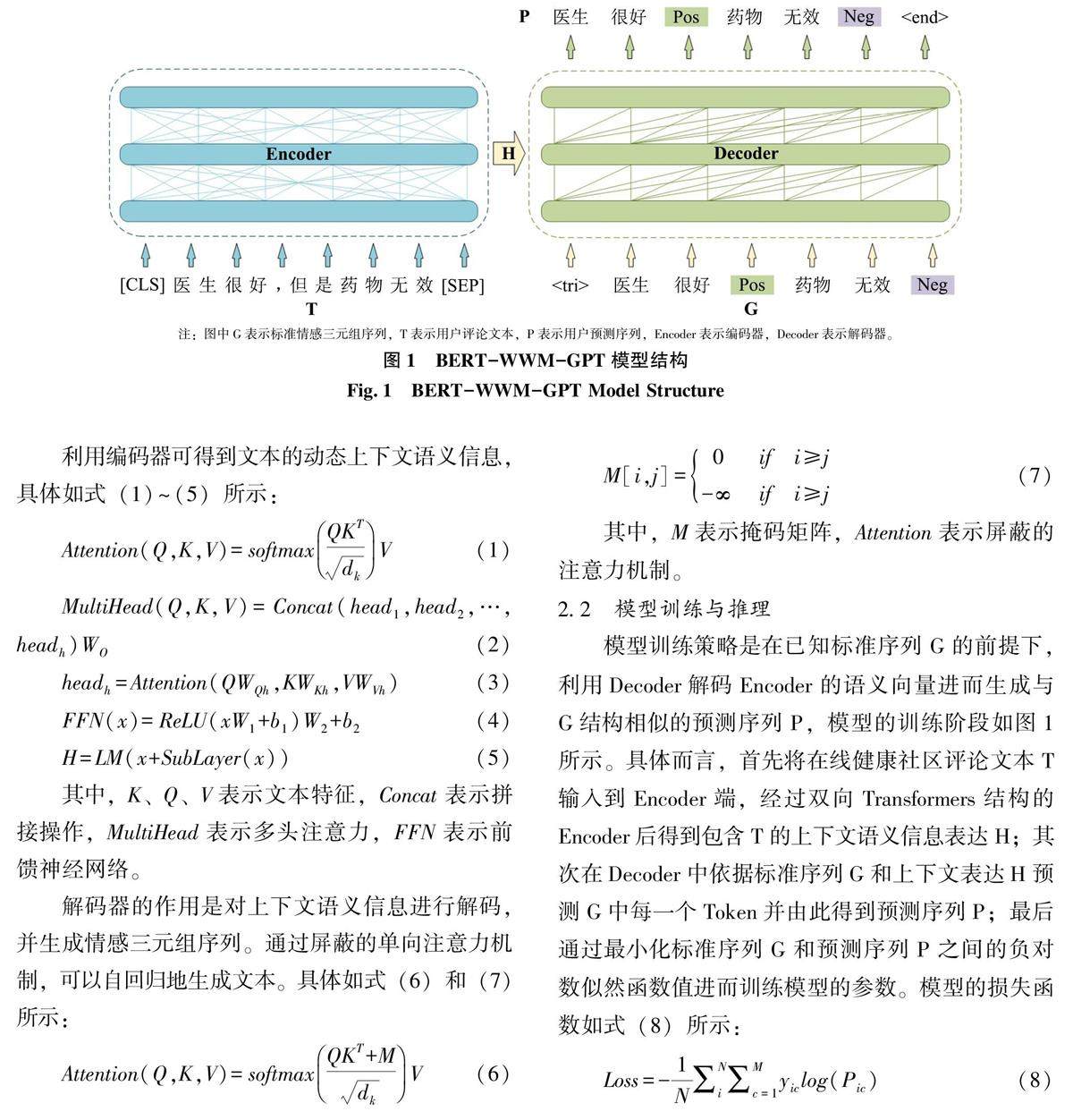
数智健康与智慧医养 | 面向在线健康社区的生成式方面级情感分析
数智健康与智慧医养 | 面向在线健康社区的生成式方面级情感分析
-
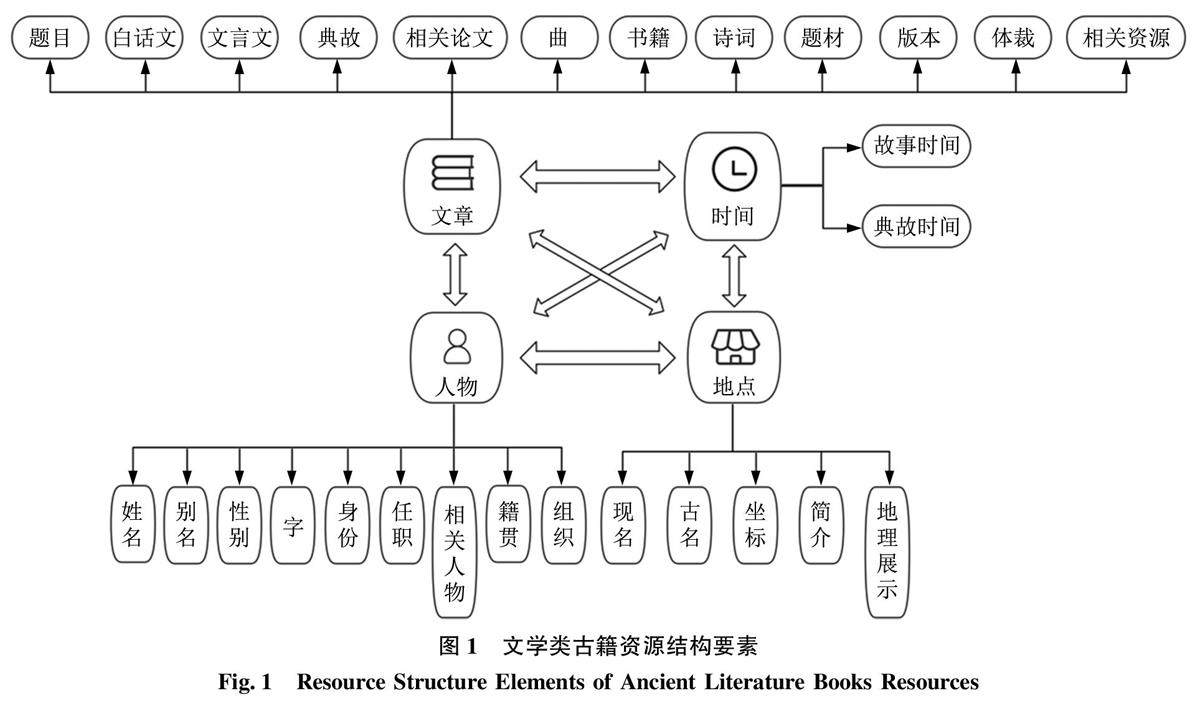
数字人文与古籍管理 | 融合GPT技术和用户需求的文学类古籍资源关联数据发布研究
数字人文与古籍管理 | 融合GPT技术和用户需求的文学类古籍资源关联数据发布研究
-
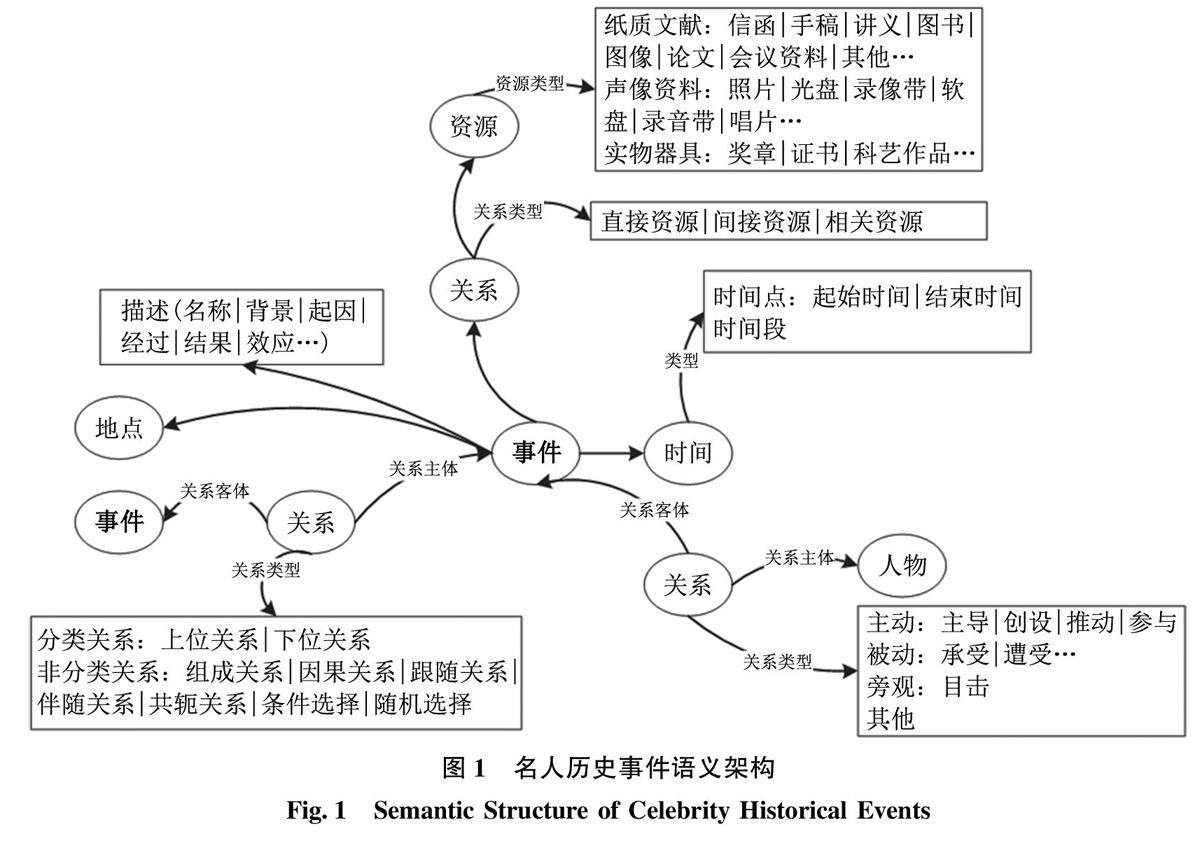
数字人文与古籍管理 | 基于口述历史资源的名人历史事件语义模型构建及实证研究
数字人文与古籍管理 | 基于口述历史资源的名人历史事件语义模型构建及实证研究





















 登录
登录